Mange naturlige fænomener i verden (fx personers højde eller fejl i målinger på fabrikker) siges at være normalfordelte. I dette indlæg kan du lære, hvad normalfordeling er. Som du kan læse fra overskriften, introducerer vi dig bl.a. for termer som middelværdi, standardafvigelse og kontinuert fordeling.
Vi kommer ind på:
Hvad betyder normalfordeling?
Middelværdi, standardafvigelse og varians
Diskrete og kontinuerte fordelinger
Normalfordeling: GeoGebra
Standardnormalfordeling
Hvad betyder normalfordeling?
Normalfordeling er en type sandsynlighedsfordeling, som man støder på i sandsynlighedsregning og statistik. Normalfordeling er kendetegnet ved at tage form som en klokkeformet kurve:
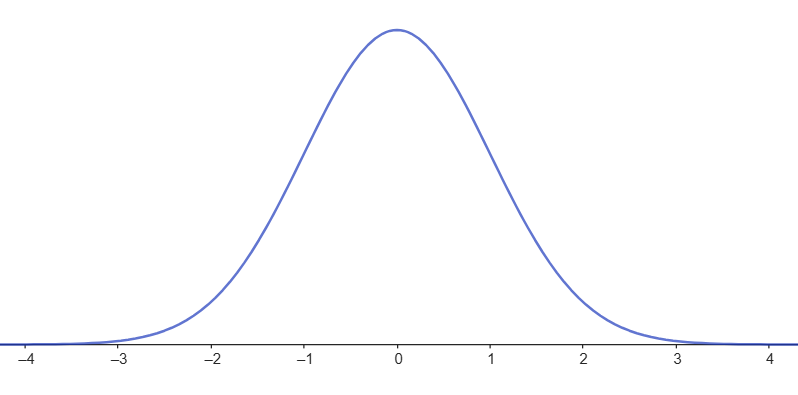
Måske har du lavet statistiske undersøgelser, hvor du fx har beregnet gennemsnitshøjden på elever i en gymnasieklasse og lavet et histogram, der viser fordelingen af, hvor høje eleverne er. Typisk vil de fleste ligge tæt på gennemsnittet, mens få vil være noget lavere eller noget højere. Man kan derfor få et histogram, som nogenlunde passer til den klokkeformede kurve, som illustreret her:
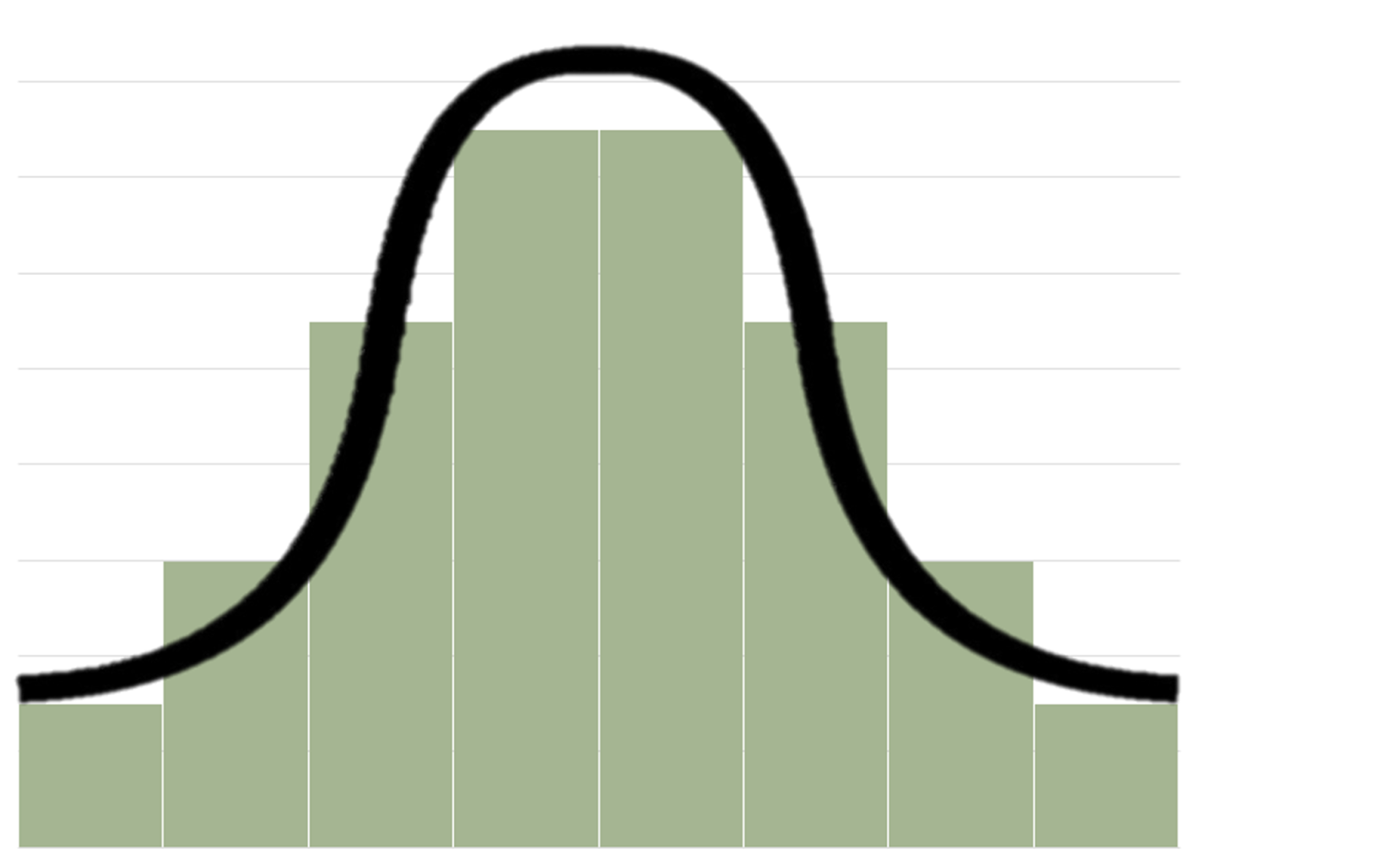
Der vil selvfølgelig være forskel, hvis du sammenlignede højderne på eleverne i én gymnasieklasse med en anden gymnasieklasse – især hvis den ene klasse havde en overvægt af piger, mens den anden klasse havde en overvægt af drenge.
Men forestil dig så, at vi lavede et histogram over højderne på alle voksne mennesker i Danmark. Her ville de mange observationer passe bedre med den klokkeformede kurve.
Normalt siger man, at data er normalfordelt, hvis histogrammet tilnærmelsesvis danner en klokkeform, men egentlig er det selve kurven, der udgør normalfordelingen. Normalfordelingen skal derfor ses som en model, der fortæller os, hvordan en stor mængde data rent statistisk vil fordele sig omkring gennemsnittet – altså både hvad gennemsnittet er, og hvor stor spredningen er.
Man bestemmer således normalfordelingen ud fra to parametre: dens middelværdi (gennemsnit) og standardafvigelse (spredning). Man betegner middelværdien med μ (det græske bogstav ‘my’), og man betegner standardafvigelsen med σ (det græske bogstav ‘sigma’).
Middelværdien angiver kurvens toppunkt. Det er her, de fleste observationer ligger. Jo længere man bevæger sig ud ad kurvens “haler”, desto færre observationer er der. Fordi normalfordelingen er fuldstændig symmetrisk, ligger medianen (den midterste observation) samme sted som middelværdien.
Standardafvigelsen viser, hvor spredte data er omkring middelværdien (altså hvor langt væk de ligger fra middelværdien). Formen på den klokkeformede kurve afhænger af standardafvigelsen. Når kurven er høj og smal, betyder det, at standardafvigelsen er lille, og når kurven er bred og lav, betyder det, at standardafvigelsen er stor.
Middelværdi, standardafvigelse og varians
Hvordan finder man så middelværdien og standardafvigelsen? Du har sikkert før skulle beregne et gennemsnit (middelværdi) i statistik og ved, at man lægger alle observationerne sammen og derefter dividerer med det samlede antal observationer.
Lad os tage et simpelt eksempel. Det har regnet hele weekenden, så vi har tilbragt weekenden med at se fem film. Vi har noteret os filmenes spilletid (længde) i antal minutter:
99 minutter
112 minutter
118 minutter
137 minutter
174 minutter
Vi beregner gennemsnitslængden og får dermed middelværdien:
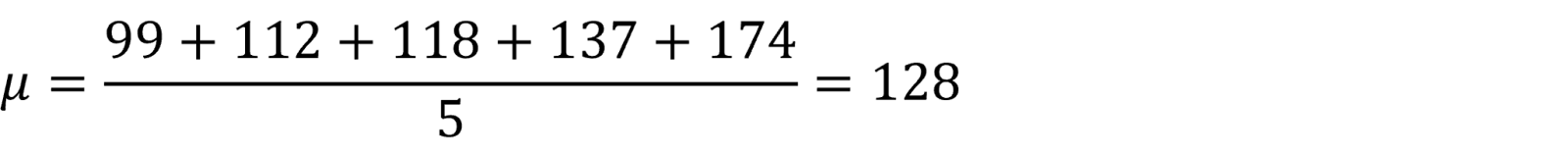
Altså var filmene i gennemsnit 128 minutter lange.
Man finder standardafvigelsen ved at tage kvadratroden af variansen. Variansen er gennemsnittet af de kvadrerede afvigelser fra middelværdien.
I vores eksempel betyder det, at vi skal trække middelværdien fra hver af de fem længder (dermed finder vi afvigelserne), opløfte dette i anden potens (dermed finder vi kvadratet af afvigelserne), og så tage gennemsnittet af disse (dermed ender vi med variansen).
Først beregner vi afvigelserne:
99 - 129 = -29
112 - 129 = -16
118 - 129 = -10
137 - 129 = 9
174 - 129 = 46
Disse sætter vi i anden og tager gennemsnittet:
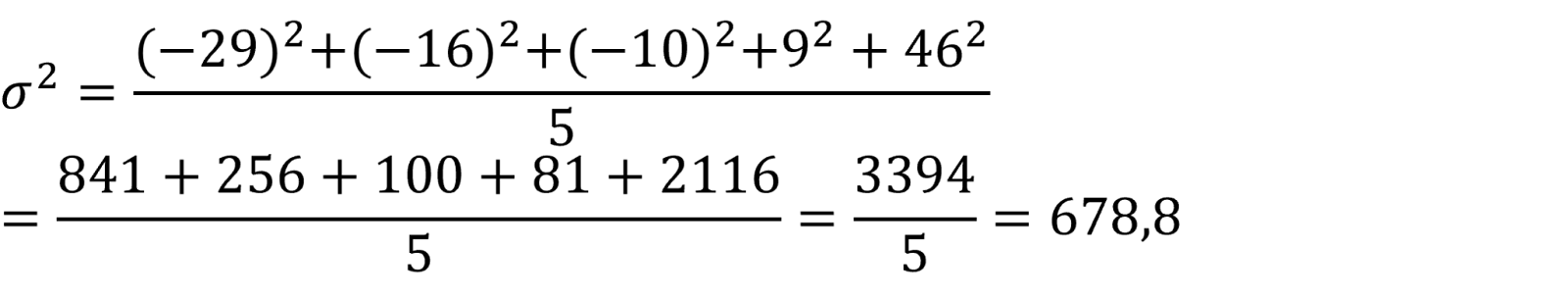
Bemærk, at variansen skrives som σ2 (altså standardafvigelsen (σ) opløftet i anden), for som nævnt er standardafvigelsen kvadratroden af variansen.
Læg også mærke til, at vi opløfter i anden, så vi ikke længere har nogen negative værdier, fordi minus gange minus giver plus.
Vi kender nu variansen og kan beregne standardafvigelsen:

Vi beregner standardafvigelsen til at være cirka 26 minutter. Dette kan vi bruge til at vise, hvilke film der havde en spilletid, som ligger inden for standardafvigelsen. Før beregnede vi de enkelte afvigelser fra middelværdien for hver film:
99 - 129 = -29
112 - 129 = -16
118 - 129 = -10
137 - 129 = 9
174 - 129 = 46
Her kan vi se, at filmene på 112 minutter, 118 minutter og 137 minutter ligger inden for standardafvigelsen (som er cirka 26 minutters forskel fra middelværdien). Filmen på 99 minutter var en anelse kortere, mens filmen på 174 var noget længere.
Standardafvigelsen kan dermed fortælle os, hvad der anses for en normal længde spillefilm, og hvad der anses for en kort film eller en lang film. Vi har kun sammenlignet fem film, og normalt ville man lave en større stikprøve, men pointen er, at en stikprøve skal fortælle, hvor lang en spillefilm som regel er, og hvor ofte man kan forvente at støde på ret korte eller ret lange film.
Det kan godt være svært at skelne mellem standardafvigelsen (σ) og variansen (σ2), fordi begge er angivet med det græske bogstav sigma. De bruges begge til at beskrive, hvor spredt ens data er. Standardafvigelsen er dog nemmere at forstå, fordi den er angivet i samme enhed som ens data (fx antal minutter, som i vores eksempel ovenfor).
Før vi går videre, vil vi forklare forskellen på diskrete og kontinuerte fordelinger.
Diskrete og kontinuerte fordelinger
Du har sikkert beskæftiget dig med sandsynlighedsregning. Her lærer vi fx at beregne sandsynligheden for at slå en 3’er med en terning. I sandsynlighedsregning har vi at gøre med diskrete fordelinger. Det betyder, at den stokastiske variabel X har et bestemt, afgrænset antal værdier. Når man kaster med en terning, er det kun muligt at slå 1, 2, 3, 4, 5 eller 6, og når man kaster med en mønt, er det kun muligt at slå plat eller krone. Disse er derfor diskrete stokastiske variable.
I normalfordeling har vi derimod at gøre med kontinuerte fordelinger. Det betyder, at den stokastiske variabel X har uendeligt mange værdier inden for et interval. En kontinuert stokastisk variabel kan fx være personers højde. Det er muligt at være 160 centimeter høj, og det er muligt at være 190 centimeter høj – man kan også være alt derimellem, og man kan være endnu lavere eller endnu højere. Man kan også være endnu mere præcis ved at angive en højde som 160,5 centimeter eller 160,52 centimeter. Altså er der ikke et afgrænset antal værdier, og personers højde er derfor en kontinuert stokastisk variabel.
Man siger dog, at værdierne typisk ligger inden for et interval. Som menneske er det ikke muligt at være 7 centimeter høj eller 7 meter høj. De fleste voksne ligger inden for intervallet [150;200], mens få selvfølgelig er lavere eller højere, men antallet af værdier er stadig ikke endeligt, fordi man kan medregne decimaler.
Det er sværere at finde middelværdien, når man har med intervaller at gøre. Det vil vi ikke gennemgå her. I en matematikopgave vil middelværdien og standardafvigelsen dog typisk allerede være oplyst. I stedet kan du blive bedt om at beregne, hvor stor en procentdel af observationerne der ligger inden for et bestemt interval.
Normalfordeling: GeoGebra
Man kan lave en normalfordeling i et regneprogram, såsom GeoGebra. Her åbner du sandsynlighedslommeregneren, og så viser den en normalfordeling. Her kan du indtaste, hvad middelværdien (μ) og standardafvigelsen (σ) er, og du kan beregne, hvor mange procent af observationerne ligger inden for et givent interval.
Når man har en normalfordelt stokastisk variabel X med middelværdien μ og standardafvigelsen σ, skriver man det sådan her:
X ∼ N(μ, σ)
Lad os vende tilbage til eksemplet med spilletiderne på film, hvor vi fandt en middelværdi på 128 og en standardafvigelse på 26 (vi afrunder for nemheds skyld). Vi kan fx beregne sandsynligheden for, at en film har en spilletid, der er mellem 90 og 120 minutter:
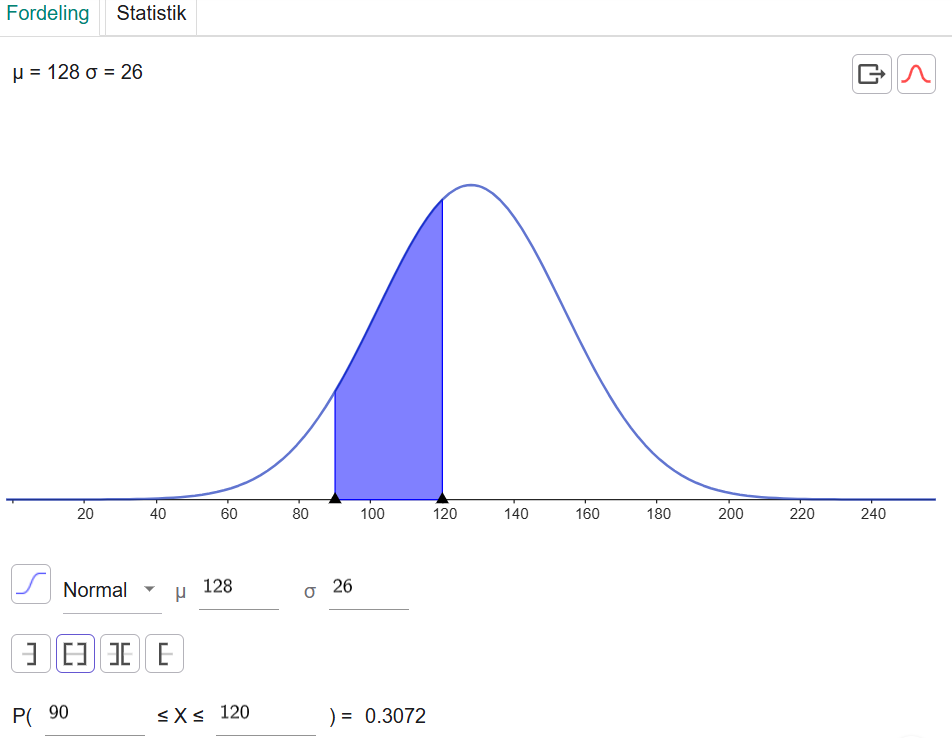
Ud fra vores beregninger er der 30,72 % sandsynlighed for, at en film varer mellem 90 og 120 minutter.
Vi kan skrive det op således: For en normalfordeling X ∼ N(128, 26) gælder det, at:
P(90 ≤ X ≤ 120) = 30,72 %
Tegnet ≤ betyder ‘større end eller lig med’ og bruges til at vise, hvad sandsynligheden er, for at X ligger inden for dette interval.
Hvis du har en opgave, hvor du bliver bedt om at beregne sandsynligheden for, at X blot er mindre end eller lig med fx 100, står det sådan her:
P(X ≤ 100)
Ligeledes hvis X er større end eller lig med fx 100:
P(X ≥ 100)
I GeoGebra kan du altså vælge, om du vil finde et interval, om det skal være venstresidet (hvis X er mindre end eller lig med en given værdi) eller højresidet (hvis X er større end eller lig med en given værdi). Det gør du ved disse knapper:
Vi kan blive bedt om at beregne sandsynligheden for, at en film har en spilletid op til én standardafvigelse kortere end middelværdien eller op til én standardafvigelse længere end middelværdien – det vil sige op til 26 minutter kortere eller længere.
Vi trækker 26 fra og lægger 26 til de 128 minutter og taster det ind i GeoGebra.
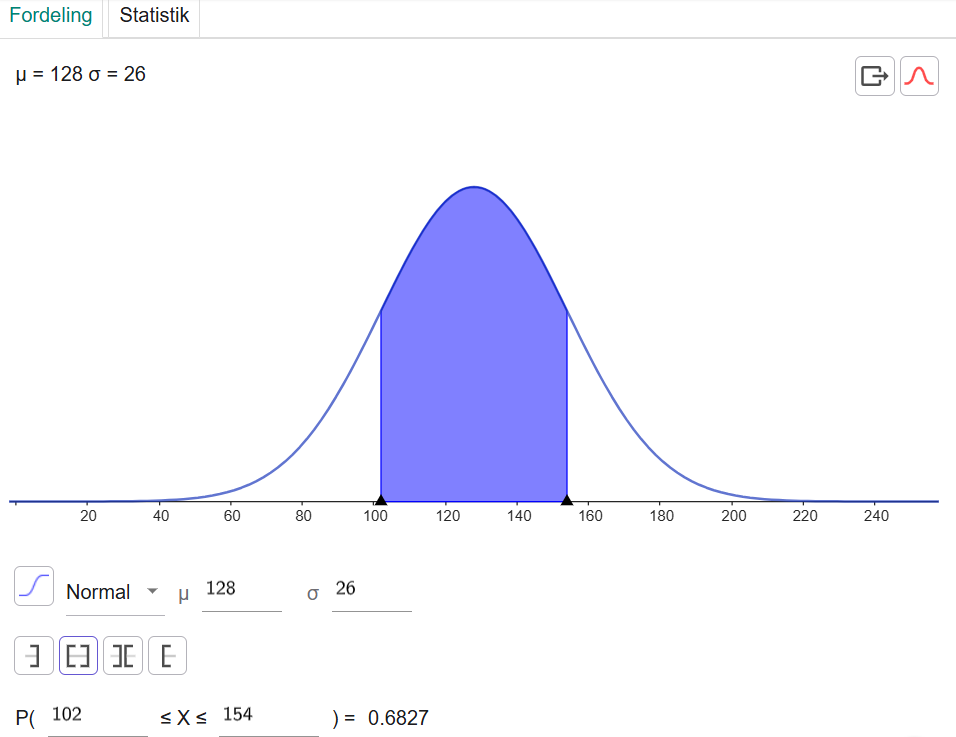
Sådan har vi beregnet, at der er 68,27 % sandsynlighed for, at en film har en længde, som ligger inden for én standardafvigelses afstand til middelværdien. Det skriver vi på denne måde:
P(102 ≤ X ≤ 154) = 68,27 %
Standardnormalfordeling
Som nævnt kan kurverne for normalfordelinger se forskellige ud i højde og bredde, alt efter hvor stor standardafvigelsen er, og værdierne på x-aksen ændrer sig, alt efter hvilke værdier middelværdien og standardafvigelsen har.
Den mest simple normalfordeling kaldes standardnormalfordelingen. For standardnormalfordelingen gælder det, at X ∼ N(0, 1) – altså at middelværdien er 0, og standardafvigelsen er 1. Her kan vi også beregne, hvor mange af observationerne der ligger med én standardafvigelses afstand fra middelværdien til hver side – det vil sige i intervallet [-1; 1].
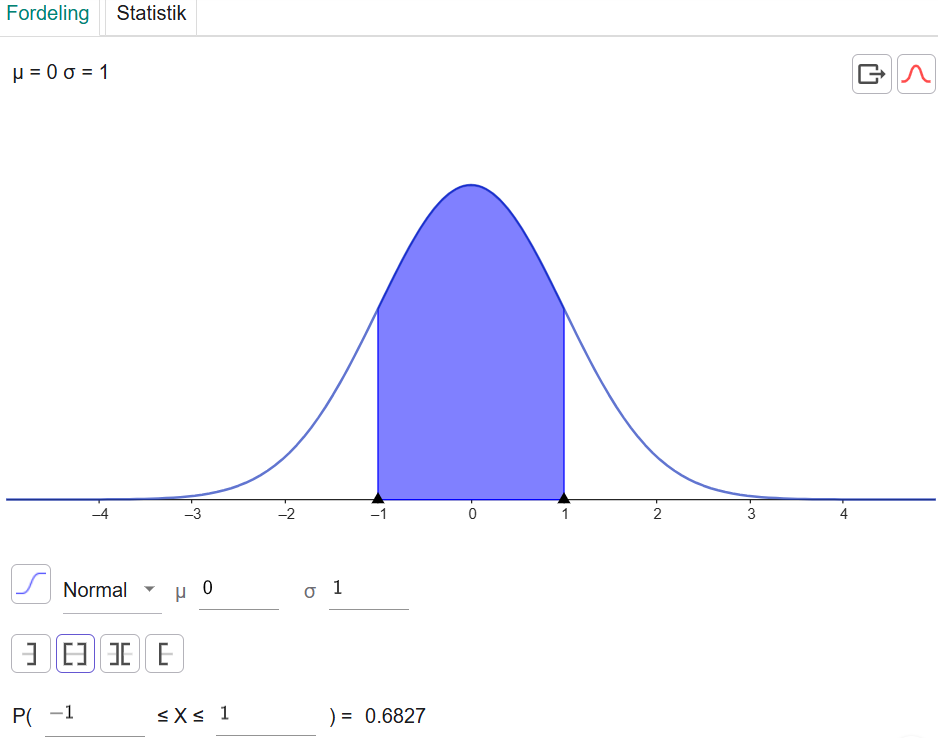
Se nu der! Det blev 68,27 % ligesom før.
Det er faktisk noget andet, der er særligt ved normalfordelinger. Uanset hvor smal eller bred kurven er, gælder det, at:
Ca. 68 % af observationerne ligger inden for én spredning på hver side af middelværdien.
Ca. 95 % af observationerne ligger inden for to spredninger på hver side af middelværdien.
Ca. 99,7 % af observationerne ligger inden for tre spredninger på hver side af middelværdien.
Sagt med almindelige ord gælder det for enhver værdi, at det er sandsynligt, at en observation vil ligge inden for én spredning; det er meget sandsynligt, at en observation vil ligge inden for to spredninger; og det er næsten sikkert, at en observation vil ligge inden for tre spredninger.
Tæthedsfunktionen og fordelingsfunktionen
Vi har gemt det sværeste til sidst, så dette afsnit kan du se bort fra, hvis du ikke har haft om det i matematiktimerne.
Vi har set, hvordan man kan få GeoGebra til at beregne sandsynlighedsfordelingen, men vi vil nu gennemgå de beregninger, der ligger bag.
Man beregner sandsynlighedsfordelingen for en kontinuert fordeling med en funktion – nærmere bestemt tæthedsfunktionen (også kaldet frekvensfunktionen). Tæthedsfunktionens graf viser sig som den klokkeformede kurve.
Tæthedsfunktionen har denne formel:

Tegnet 𝜋 er pi med en værdi på cirka 3,14, og tegnet e er Eulers tal med en værdi på cirka 2,71828. Derudover skal vi som bekendt kende middelværdien (μ) og standardafvigelsen (σ). Den resterende variabel er x, og man kan sætte forskellige værdier ind på x’s plads.
Vi skal dog ikke bestemme sandsynligheden for, at en observation forekommer i et punkt, men derimod i et interval.
Ved at integrere tæthedsfunktionen får man fordelingsfunktionen, og denne kan man bruge til at beregne, hvor stor en procentdel af ens observationer der ligger i et givent interval. Formlen for fordelingsfunktionen er dermed:

Funktionen gør, at arealet under kurven svarer til 1, så ethvert interval vil ligge mellem 0 og 100 %.
Lad os beregne et eksempel. Vi tager udgangspunkt i standardnormalfordelingen, hvor middelværdien som bekendt er 0, og hvor standardafvigelsen er 1. Hvis vi sætter 0 og 1 ind på henholdsvis μ’s og σ’s i tæthedsfunktionen, vil den se sådan her ud:

Vi vælger at beregne sandsynligheden for, at en observation ligger i intervallet [0; 1].

Der er dermed 34,14 % sandsynlighed for, at en observation ligger i intervallet [0; 1].
Selve udregningen er svær, og som vi har set, kan vi nemt bruge GeoGebra til at lave vores udregninger, men nu har du set formlen bag, og hvordan man skriver det op.
Hvis du stadig ikke føler, at du har helt styr på normalfordeling (eller andre emner inden for matematik), tilbyder GoTutor lektiehjælp i matematik.