En chi i anden-test er en type statistisk test, som du sikkert har haft om i matematiktimerne. Hvis du sidder med aflevering og skal lave en chi i anden-test, kan du læse i dette indlæg, hvordan man gør. Vi gennemgår to typer chi i anden-test: goodness of fit og uafhængighedstest.
Vi kommer ind på:
Hvad viser chi i anden-test?
Chi i anden-test: Goodness of fit
Chi i anden-test: Uafhængighedstest
Hvad betyder signifikansniveau på 5 %?
Hvad viser chi i anden-test?
En chi i anden-test bruges til at vise, om visse data skyldes tilfældigheder, eller om der kan findes en sammenhæng. Man skriver det også som χ²-test (χ er det græske bogstav chi, som udtales "ki").
Der findes to former for χ²-test. Den ene kaldes goodness of fit, hvor man måler overensstemmelsen mellem en række observerede værdier og de forventede værdier. Den anden form kaldes en uafhængighedstest, hvor man måler, om der er uafhængighed mellem to variable.
Man laver en goodness of fit, når ens data kommer i en liste over observerede værdier. Man laver en uafhængighedstest, når ens data kommer i en krydstabel.
Sammenlign disse data:

I den blå tabel har en bager solgt 100 kager på en dag og noteret sig, hvilken slags kage kunderne købte. Vi kan lave en goodness of fit for at teste, hvordan denne fordeling af kager stemmer overens med forventningen om, at bageren ville sælge lige mange af hver slags kage.
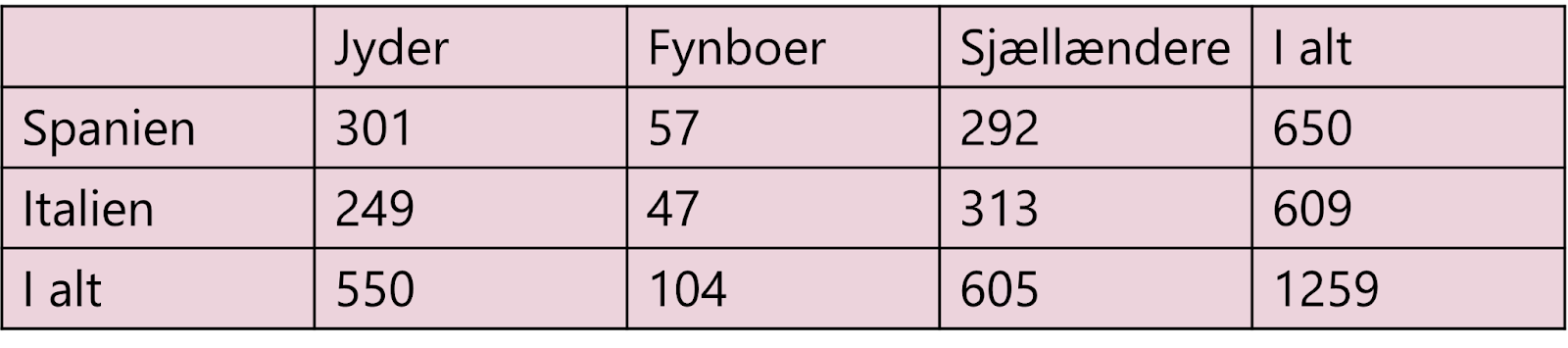
I den lyserøde tabel forestiller vi os, at vi har spurgt 1.259 danskere, hvor de bor i landet (enten Jylland, Fyn eller Sjælland), og om de foretrækker at holde ferie i Spanien eller Italien. Vi kan lave en uafhængighedstest for at teste, om der er sammenhæng mellem, hvor i landet man bor, og hvor man foretrækker at holde ferie.
Vi vil gennemgå hvert eksempel nedenfor. Først skal du kende nogle vigtige termer, som man bruger i statistiske test, herunder χ²-test:
Nulhypotese: Antagelsen om, at de observerede værdier skyldes ren tilfældighed. Nulhypotesen kaldes H0.
Observerede værdier: De data, som vi har fået i eksperimentet.
Forventede værdier: De værdier, som vi ville forvente at få, hvis vi antog nulhypotesen.
Teststørrelse: Et tal, der fortæller os, hvor godt vores observerede værdier passer med de forventede værdier.
P-værdi: Sandsynligheden for at få et udfald, der er mindst lige så skævt som det observerede (i forhold til det forventede).
Signifikansniveauet: Den sandsynlighed, der bestemmer grænsen for, hvornår nulhypotesen forkastes (ofte 5 %). Nulhypotesen forkastes, hvis p-værdien er mindre end signifikansniveauet.
OBS: Man kan kun forkaste (eller ikke forkaste) H0. Man har ikke "bevist", at H0 er sand, bare fordi man ikke forkaster den.
Bare rolig – vi gennemgår termerne igen, efterhånden som vi bruger dem, men ovenstående skal ses som en oversigt.
Chi i anden-test: Goodness of fit
Først vil vi gennemgå, hvordan man laver den ene slags χ²-test: goodness of fit. Vi bruger eksemplet med kagerne.
Vi forestiller os, at vi har bedt en bager om at notere, hvor mange kager af hver slags hun sælger i løbet af en dag. Vi kan lave en goodness of fit for at teste, hvordan denne fordeling af kager stemmer overens med forventningen om, at bageren ville sælge lige mange af hver slags kage.

Først opstiller vi en nulhypotese (H0). Den lyder, at bageren forventer at sælge lige mange af hver slags kage. Bageren har solgt 100 kager, og med fire forskellige slags ville det betyde, at hun skulle have solgt 25 af hver slags, hvis fordelingen havde været helt lige.

Man tager altså summen af observationerne og dividerer med antal værdier.
Næste trin er at beregne χ²-teststørrelsen. Det gør vi med denne formel:
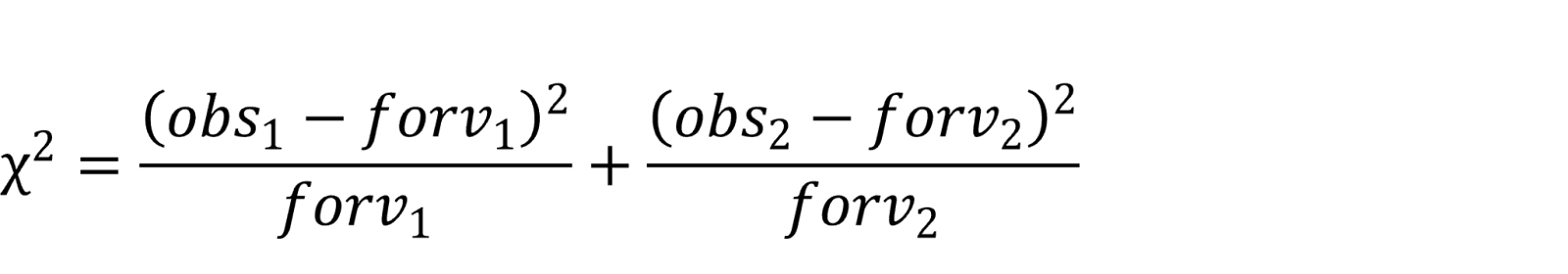
Formlen udvides efter antal værdier, som i dette tilfælde er fire (fire slags kager). Vi sætter de observerede værdier og de forventede værdier ind i formlen:
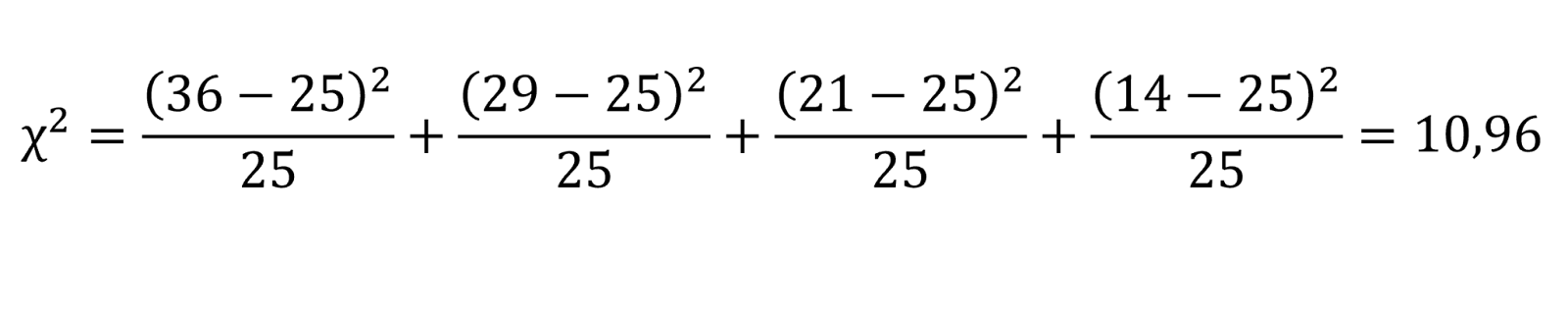
Vi har dermed beregnet vores teststørrelse til at være 10,96.
Dernæst finder vi p-værdien, som er sandsynligheden for at få et udfald, der er mindst lige så skævt som det observerede – i forhold til det forventede.
Jo mindre teststørrelsen er, desto større er p-værdien. Teststørrelsen beskriver, hvor godt de observerede værdier passer til de forventede værdier. Jo større p-værdien er, desto tættere er man på nulhypotesen omkring en ligelig fordeling.
Er p-værdien derimod for lav, må vi forkaste nulhypotesen – det vil sige, at vi antager, at de observerede værdier er for skæve til blot at kunne være en tilfældighed, og at der derfor må være en sammenhæng mellem dataene. Derfor fastlægger vi et signifikansniveau på 5 %. Signifikansniveauet bestemmer grænsen for, hvornår nulhypotesen forkastes. At det er 5 % betyder, at en p-værdi mindre end dette medfører, at vi må forkaste nulhypotesen.
Vi finder p-værdien ved hjælp af programmet GeoGebra, som du kan finde online. Vi går ind under ‘Sandsynlighed’ → ‘Statistik’ og vælger ‘Goodness of Fit Test’ fra listen (i den klassiske version af GeoGebra – det ser muligvis anderledes ud i andre versioner). Vi vælger 4 rækker, så det passer til vores liste. Her indtaster vi de observerede og forventede værdier, og så beregner programmet både χ²-teststørrelsen og p-værdien.

Som vist på billedet ovenfor stemmer GeoGebras udregning af teststørrelsen overens med den beregning, som vi har foretaget med formlen, altså at teststørrelsen er 10,96. GeoGebra beregner også vores p-værdi, som er 0,0119 – eller 1,19 %.
Inden vi konkluderer på denne p-værdi, vil vi vise, at p-værdien også kan illustreres på en kurve. Til det skal vi bruge antallet af frihedsgrader. Frihedsgrader er det antal data i listen, som frit kan variere.
Som du kan se på billedet, har GeoGebra beregnet vores antal frihedsgrader til at være 3 (df står for ‘degrees of freedom’), men for god ordens skyld viser vi, hvordan man selv kan beregne antallet af frihedsgrader.
Når frihedsgraderne er bestemt, er de resterende data i listen fastlagt, da det skal passe med summen. I vores tilfælde betyder det, at vi har fire observerede værdier som det samlede antal, men egentlig er det nok kun at kende tre af værdierne, for når vi kender summen, kender vi også den sidste værdi. Derfor er vores antal af frihedsgrader 3. Mere generelt siger man:

Her er m observerede værdier.
Vi har altså tre frihedsgrader, og det indtaster vi i sandsynlighedslommeregneren i GeoGebra under ‘Fordeling’. Her skal vi vælge ‘Chi i anden’ fra listen, og vi skal vælge, at fordelingen skal være højresidet. Derudover indtaster vi χ²-teststørrelsen.
GeoGebra finder 10,96 på x-aksen og beregner arealet af det farvede stykke. Dette giver p-værdien, fordi det farvede stykke under kurven viser de udfald, som er mindst lige så skæve som de observerede.
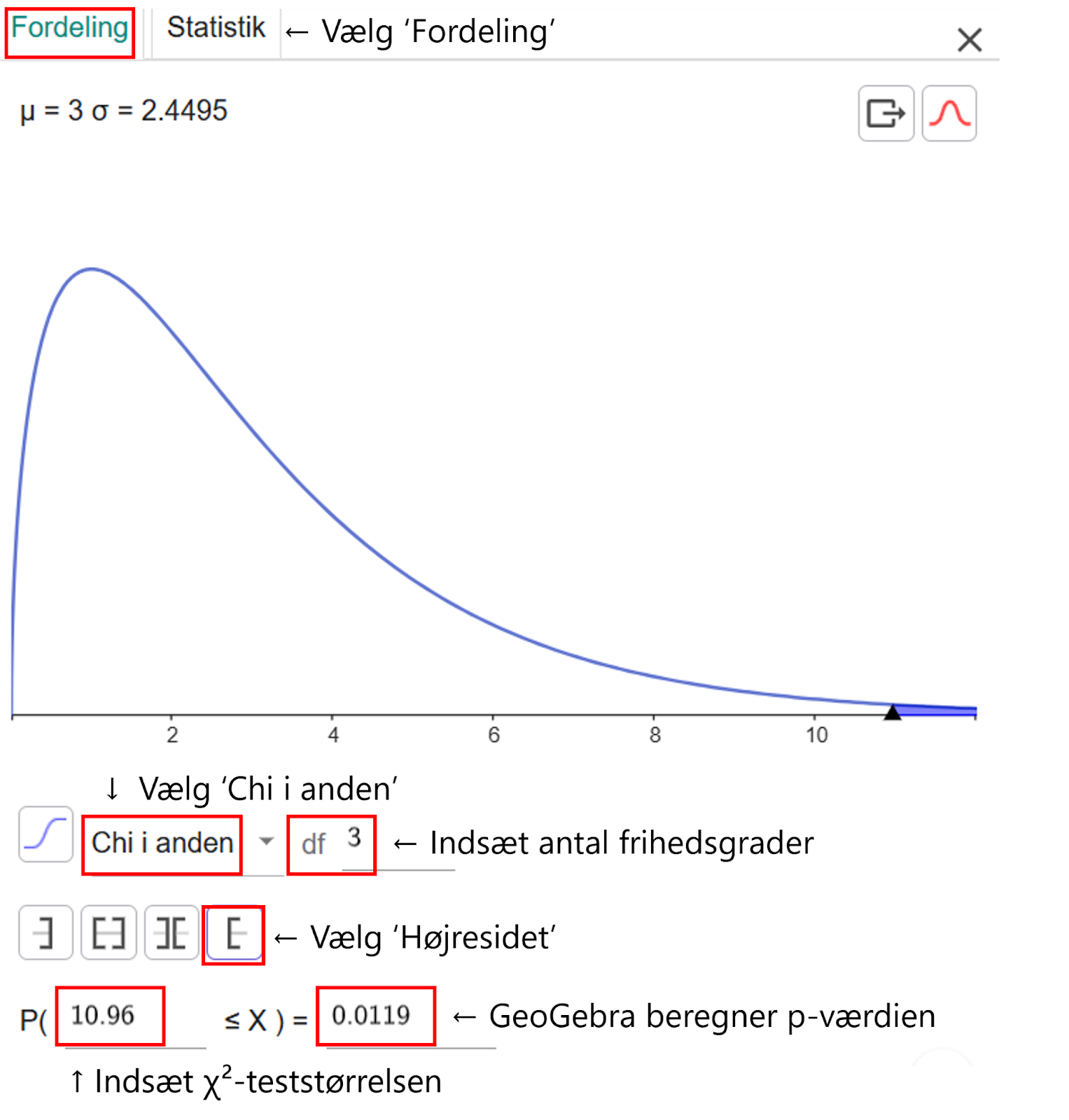
P-værdien beregnes som nævnt til at være 0,0119 eller 1,19 %. Dette er under signifikansniveauet på 5 %. Derfor konkluderer vi, at nulhypotesen kan forkastes, og at bageren ikke har solgt en ligelig fordeling af kager. Helt præcist er der 1,19 % sandsynlighed for, at bageren ville sælge en mindst lige så skæv fordeling af kager, som hun gjorde denne dag.
Chi i anden-test: Uafhængighedstest
Nu vil vi gennemgå, hvordan man laver den anden slags χ²-test: uafhængighedstest. Vi bruger eksemplet med bopæle og feriedestinationer.
Vi forestiller os, at vi har spurgt 1.259 danskere, hvor de bor i landet (enten Jylland, Fyn eller Sjælland), og om de foretrækker at holde ferie i Spanien eller Italien. Vi kan lave en uafhængighedstest for at teste, om der er sammenhæng mellem, hvor i landet man bor, og hvor man foretrækker at holde ferie.
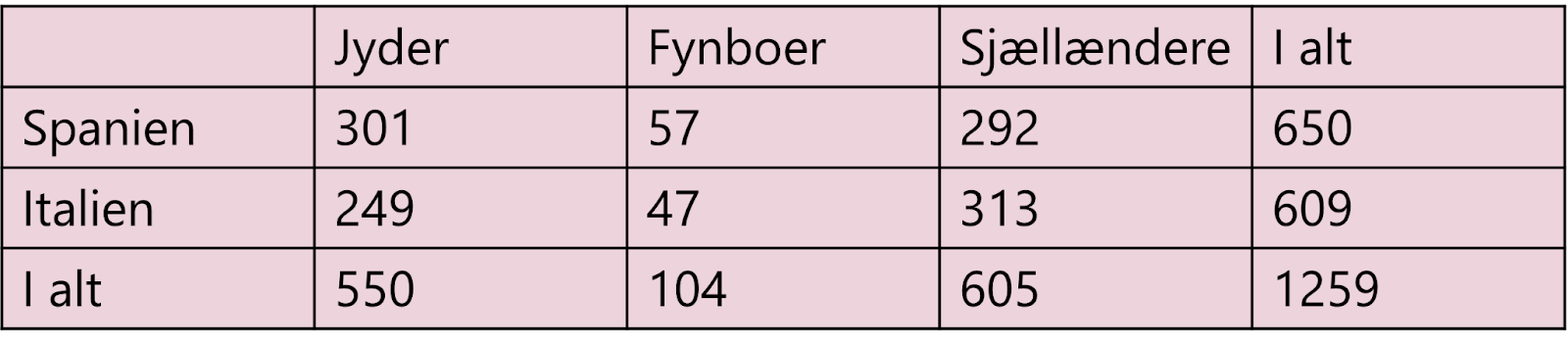
Først opstiller vi en nulhypotese (H0). Den lyder, at der ingen sammenhæng er mellem ens bopæl og ens foretrukne feriedestination.
Dernæst skal vi beregne de forventede værdier. Her starter vi med at beregne, hvor stor en procentdel af jyderne, der foretrækker at holde ferie i Spanien. Til det skal vi beregne, hvor mange procent jyderne udgør af det samlede antal danskere:
550/1259 = 0,4369
Det vil sige, at 43,69 % af danskerne i dette datasæt er jyder. Dette ganger vi med summen af alle danskere, der foretrækker at holde ferie i Spanien, da vi forventer, at jyderne udgør 43,69 % af den del af danskerne, der foretrækker at holde ferie i Spanien, ligesom de udgør 43,69 % af det samlede antal danskere.
550/1259*650 = 283,96
Dette betyder, at vi forventer, at 283,96 af danskerne både er jyder og foretrækker at holde ferie i Spanien (man kan naturligvis ikke dele mennesker i mindre dele, men det er sådan, vi laver beregningen, da vi forestiller os en hypotetisk fordeling). Vi laver samme beregning for resten af dataene:

Nu har vi en tabel med de forventede værdier.
Næste trin er at beregne χ²-teststørrelsen. Det gør vi med denne formel:
Formlen udvides efter antal værdier, som i dette tilfælde er seks (tre landsdele gange to feriedestinationer). Vi sætter de observerede værdier og de beregnede forventede værdier ind i formlen:
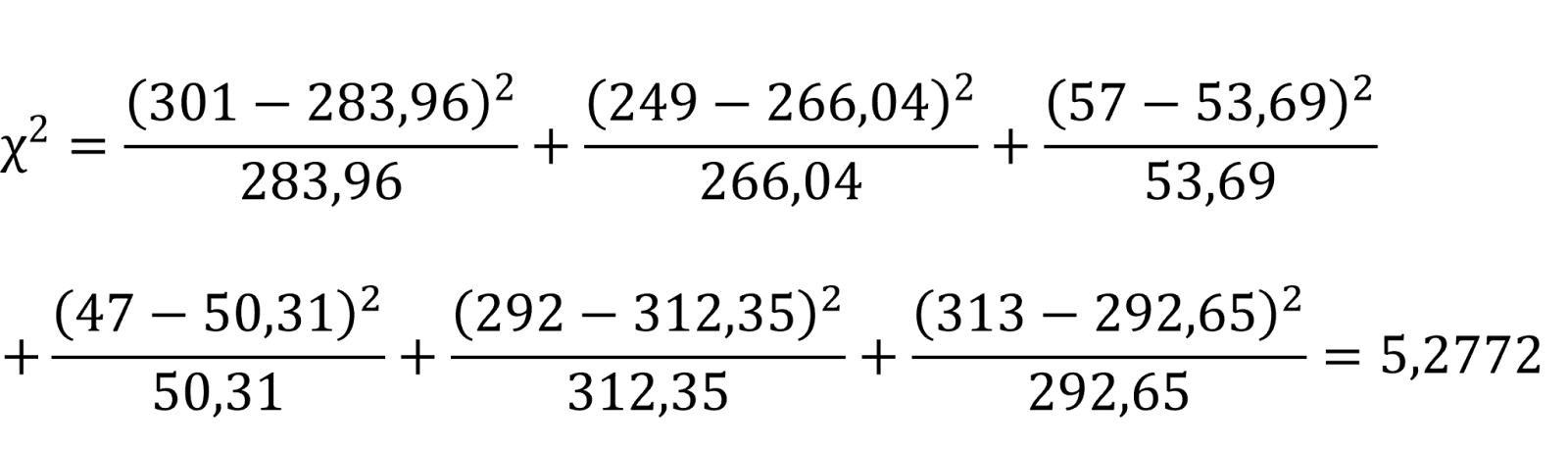
Vi har dermed beregnet vores teststørrelse til at være 5,2772.
Dernæst finder vi p-værdien, som er sandsynligheden for at få et udfald, der er mindst lige så skævt som det observerede – i forhold til det forventede.
Jo mindre teststørrelsen er, desto større er p-værdien. Teststørrelsen beskriver, hvor godt de observerede værdier passer til de forventede. Jo større p-værdien er, desto tættere er man på nulhypotesen omkring en ligelig fordeling.
Er p-værdien derimod for lav, må vi forkaste nulhypotesen – det vil sige, at vi antager, at de observerede værdier er for skæve til blot at kunne være en tilfældighed, og at der derfor må være en sammenhæng mellem dataene. Derfor fastlægger vi et signifikansniveau på 5 %. Signifikansniveauet bestemmer grænsen for, hvornår nulhypotesen forkastes. At det er 5 % betyder, at en p-værdi mindre end dette medfører, at vi må forkaste nulhypotesen.
Vi finder p-værdien ved hjælp af programmet GeoGebra. Vi går ind under ‘Sandsynlighed’ → ‘Statistik’ og vælger ‘Chi² Test’ fra listen (i den klassiske version af GeoGebra – det ser muligvis anderledes ud i andre versioner). Vi vælger to rækker og tre søjler, så det passer til vores tabel. Her indtaster vi de observerede værdier, og så beregner programmet både χ²-teststørrelsen og p-værdien. Derudover kan det også vise de forventede værdier og χ²-bidraget for hver enkel observeret værdi, altså de enkelte beregninger for hvert led i formlen for teststørrelsen.
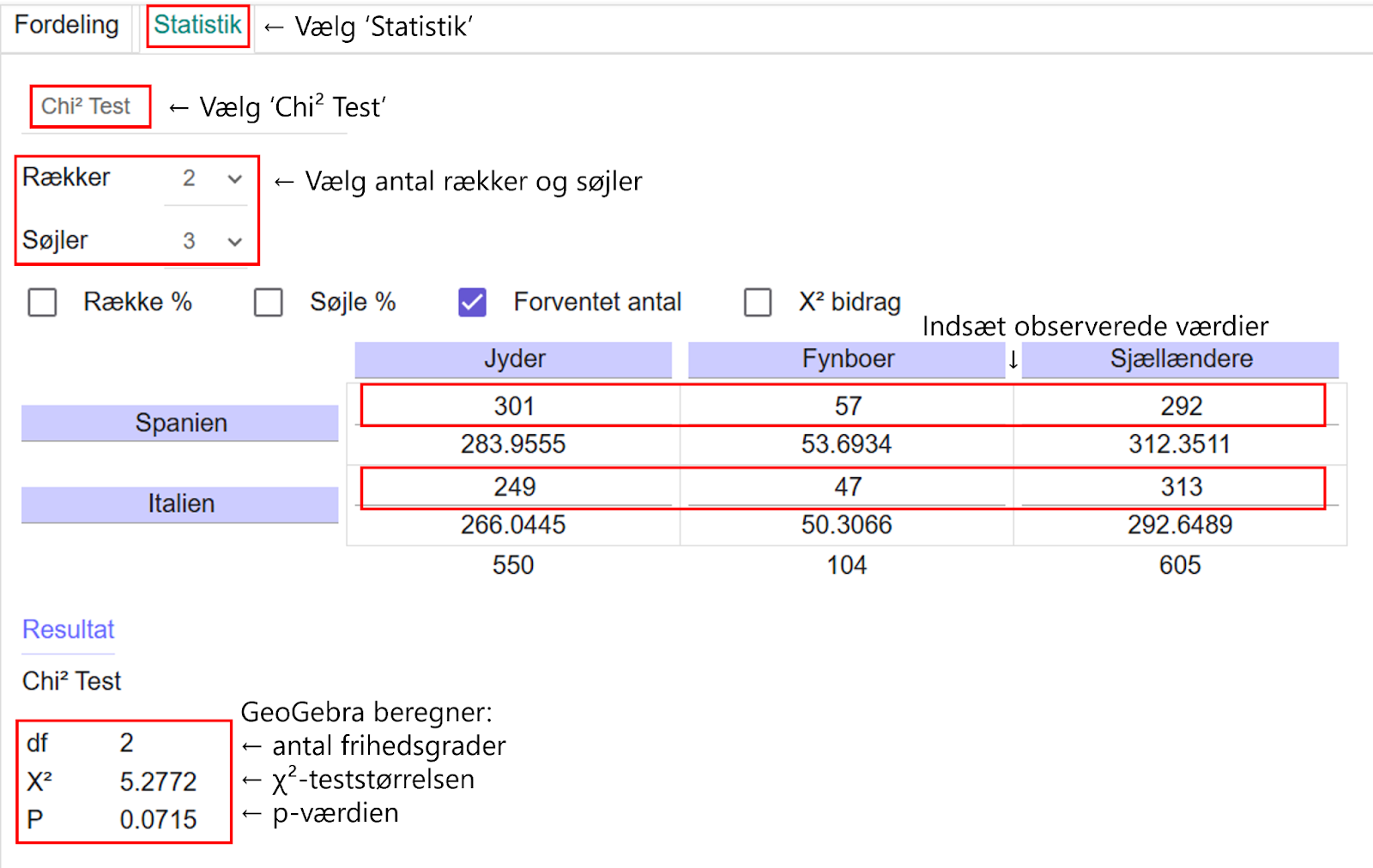
Som vist på billedet ovenfor stemmer GeoGebras udregning af teststørrelsen overens med den beregning, som vi har foretaget med formlen, altså at teststørrelsen er 5,2772. GeoGebra beregner også vores p-værdi, som er 0,0715 – eller 7,15 %.
Inden vi konkluderer på denne p-værdi, vil vi vise, at p-værdien også kan illustreres på en kurve. Først skal vi bestemme antallet af frihedsgrader. Frihedsgrader er det antal data i listen, som frit kan variere.
Som du kan se på billedet, har GeoGebra beregnet vores antal frihedsgrader til at være 2 (df står for ‘degrees of freedom’), men for god ordens skyld viser vi, hvordan man selv kan beregne antallet af frihedsgrader.
Når frihedsgraderne er bestemt, er de resterende data i tabellen fastlagt, da det skal passe med summen. Til at beregne antal frihedsgrader i en uafhængighedstest bruger vi formlen:

Her er m og n vores to variable. I tabellen svarer det til antal rækker og antal søjler. Vi sætter antallet af rækker og søjler ind i formlen:

Vi har dermed to frihedsgrader, og det indtaster vi i sandsynlighedslommeregneren i GeoGebra under ‘Fordeling’. Her skal vi vælge ‘Chi i anden’ fra listen, og vi skal vælge, at fordelingen skal være højresidet. Derudover indtaster vi χ²-teststørrelsen.
GeoGebra finder 5,2772 på x-aksen og beregner arealet af det farvede stykke under kurven. Dette giver p-værdien, fordi det farvede stykke viser de udfald, som er mindst lige så skæve som de observerede.
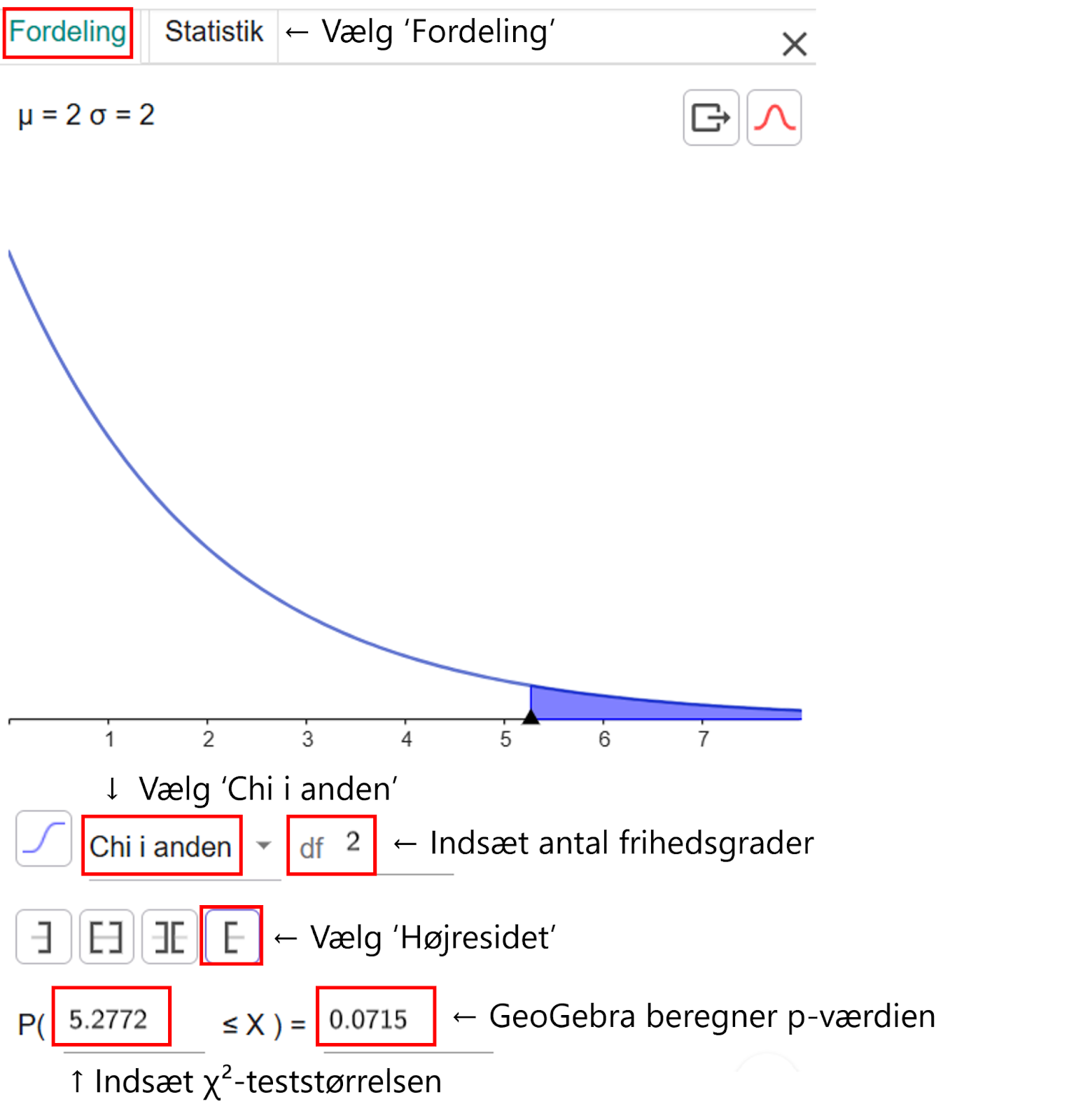
P-værdien beregnes som nævnt til at være 0,0715 eller 7,15 %. Dette er over signifikansniveauet på 5 %. Derfor konkluderer vi, at nulhypotesen ikke kan forkastes. Denne stikprøve viser dermed, at der ikke er en sammenhæng mellem, om man foretrækker Spanien eller Italien som feriedestination, alt efter om man bor i Jylland, på Fyn eller på Sjælland.
Bemærk, at vi skriver, at nulhypotesen ikke kan forkastes. Det er IKKE det samme som at skrive, at man godtager nulhypotesen.
Hvad betyder signifikansniveau på 5 %?
At vælge et signifikansniveau på 5% er blot noget man typisk gør, fordi man formindsker risikoen for at forkaste en sand nulhypotese, som jo er, at man antager, at de observerede værdier skyldes ren tilfældighed. Andre gange er risikoen større, så man sætter måske et signifikansniveau på 1 % eller endnu lavere, fx hvis man skal teste, om der er en sammenhæng mellem en ny type medicin og bivirkninger.
Fastlæggelsen af signifikansniveauet er meget afgørende for, hvilken konklusion man drager. I uafhængighedstesten konkluderede vi, at der ikke er en sammenhæng mellem ens bopæl og ens foretrukne feriedestination, fordi vi havde en p-værdi på 7,15 %. Men havde vi bestemt, at signifikansniveauet skulle være 10 %, kunne vi forkaste nulhypotesen.
Valget af signifikansniveauet kan altså tilpasses efter, hvilken konklusion man ønsker. Noget andet, som også er meget afgørende for resultatet, er antallet af observationer – i vores tilfælde i uafhængighedstesten er det antal danskere. 1.259 personer udgør blot en lille del af befolkningen, så deres præferencer reflekterer ikke nødvendigvis resten af danskerne. En bredere observation giver et mere sikkert resultat. Desuden har de blot skullet vælge mellem to lande. Uanset stikprøvens størrelse vil konklusionen stadig afhænge af ens valg af signifikansniveau.
Vi håber, at du er blevet klogere på chi i anden-test og nu kan lave din egen, men hvis du stadig mangler hjælp, kan du få skræddersyet lektiehjælp i matematik fra GoTutor.